multi-Grained Cascade Forest
深度级联森林:决策树模型具有可解释性强的优点,多个决策树构成随机森林,多层多个森林构成深度森林
gcForest是西瓜书作者周志华博士和冯霁博士提出的一基于随机森林的深度森林的方法,尝试用深度森林的方法解决深度神经网络中存在的问题:
- 需要大量样本才能使得深度神经网络有较好的性能
- 调参困难
- 对硬件性能要求较高
论文中实验了在小数据集上gcForest,取得了不错的效果
论文地址:https://arxiv.org/pdf/1702.08835.pdf
部分翻译:http://it.sohu.com/20170302/n482153688.shtml
1. 算法基本思路
gcForest是西瓜书作者周志华博士和冯霁博士提出的一基于随机森林的深度森林的方法,是一种“ensemble of ensembles”的方法。类似深度神经网络,深度森林是每层是由多个随机森林组成,每层的随机森林是由完全随机森林及随机森林组成
- 完全随机森林的构建:构建1000个(超参数)完全随机树。完全决策树的构建过程:对于所有的特征,随机选择特征,随机选择特征下的split值,一直生长,直到每个叶节点包含相同的类别或者不超过10(超参数)个时,决策树训练停止
- 随机森林的构建:构建1000个(超参数)决策树。决策树的构建过程:从\(d\)个特征,随机抽取\(\sqrt{d}\)个特证,由gini系数做为特征选择及分裂的标准构建CART决策树
每一层经过多个森林处理的输出作为下级的输入,当到达某一层没有明显的性能提升(超参数)时,级连森林停止生长
2. 算法流程
2.1. 类向量的训练
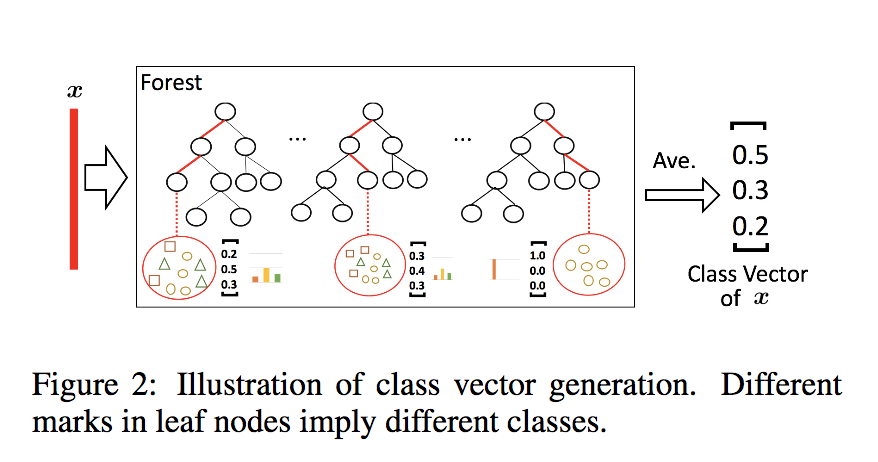
图片说明:图中有两个小bug,第一个决策树“红圈”内的叶子节点少了一个“椭圆”,第三个决策树“红圈”内应该全为“正方形”
假设为k分类问题
1,针对已经训练好的森林中的树时,记录每个叶子节点的样本类别,按类别统计叶子节点的权重得到k维向量,树模型的每个叶子节点都对应一个k维向量(带key的向量,如,label_1:0.5, label_2:0.3, lable_3=0.2)。
2,给定一个样本经过树的运算到达叶子节点,对应一个k维向量,一个随机森林中对应1000个k维向量, 将1000个k维向量按照类别求平均,平均后的k维向量即为该样本在该森林上的类向量
2.2. 级连森林训练
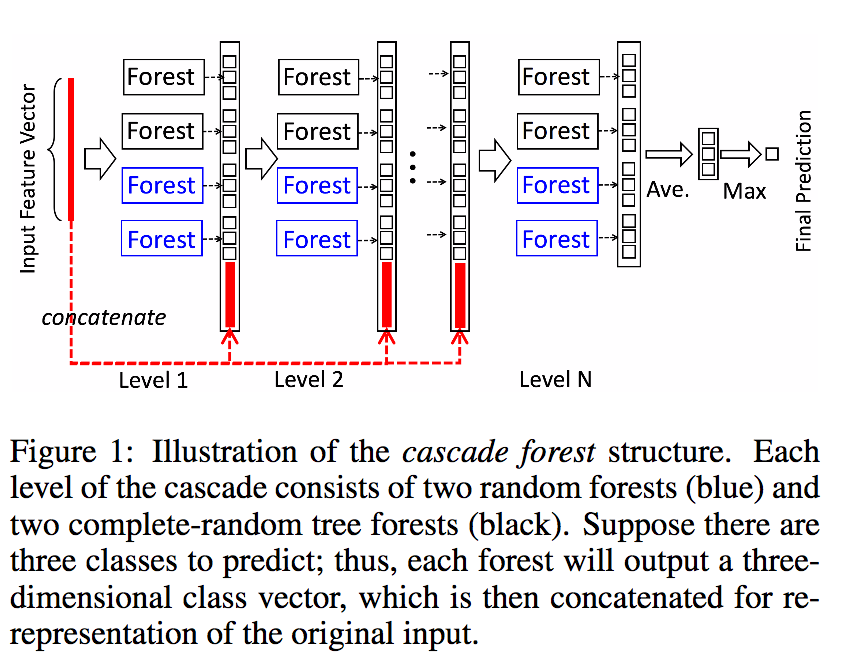
伪代码如下:
2.3. 级连森林预测
伪代码如下:
3. 使用多粒度扫描做特征处理
- 多粒度扫描结构
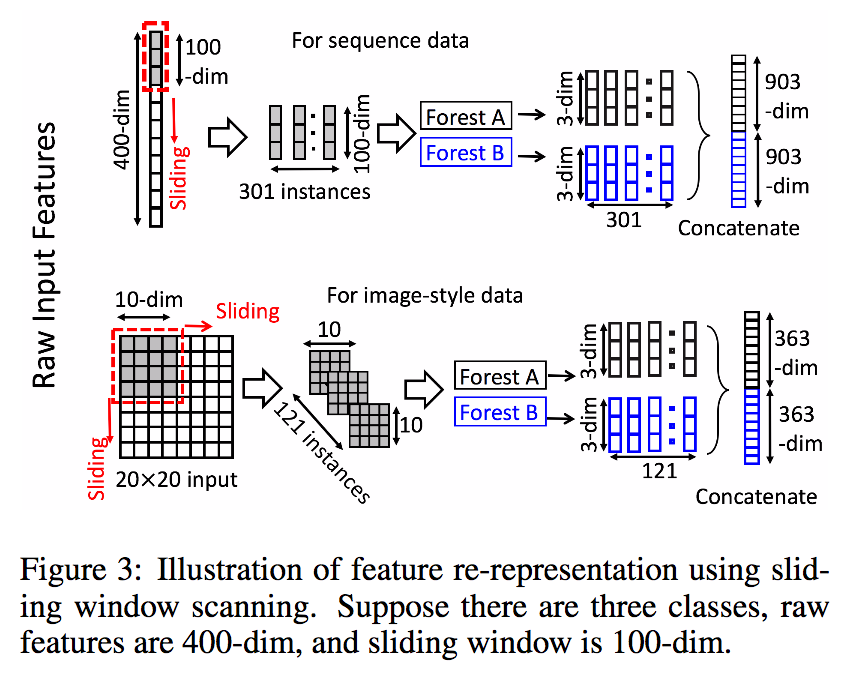
(图3,多粒度扫描示结构意图) - 带多粒度扫描的级连森林结构
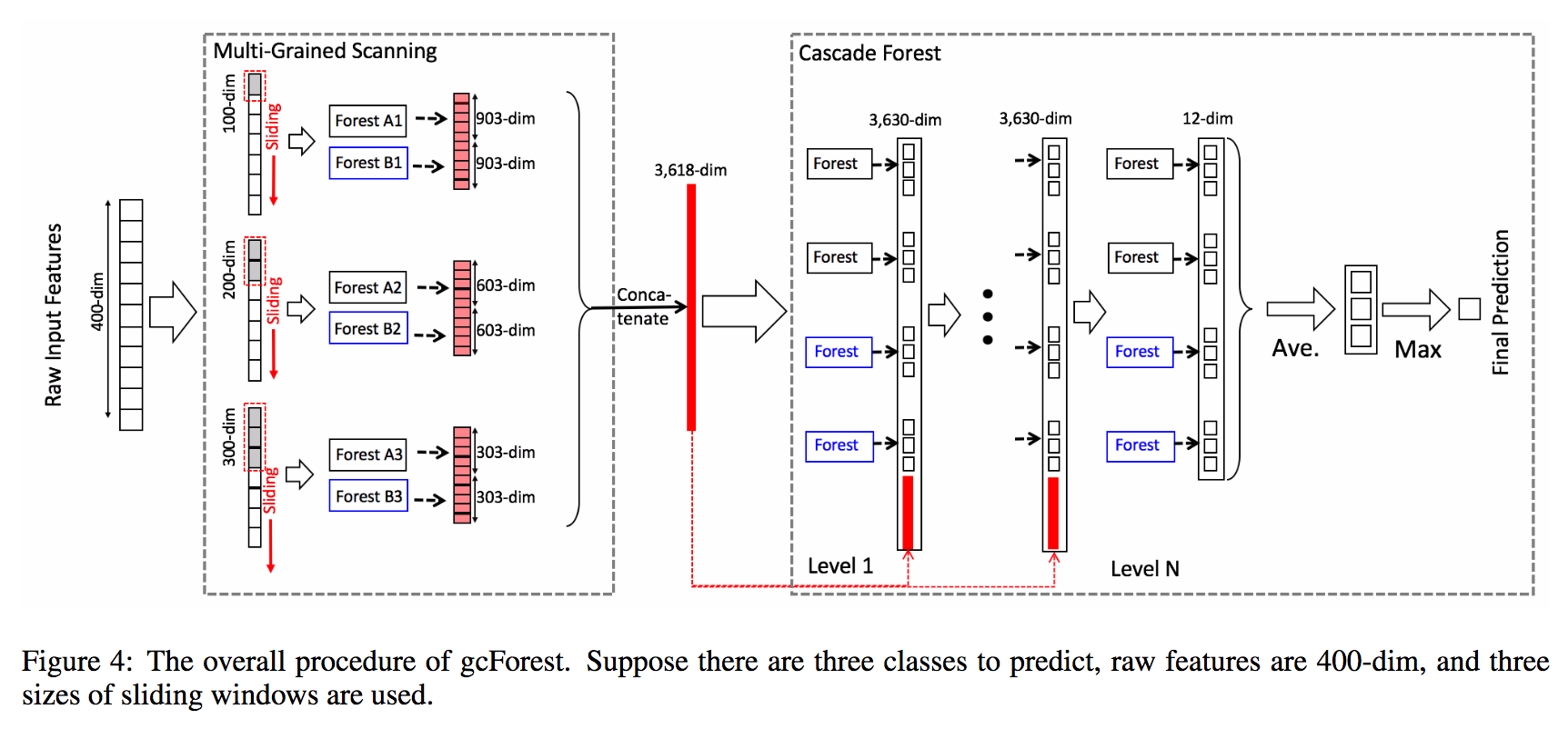
(图4,带多粒度扫描的增强级连森林示结构意图) - 描述:
类似卷机神经网络的Pooling,深度森林也引入“滑动窗口”,替代pooling层的方法max-pooling, mean-pooling的计算方式为多个森林(完全随机森林和随机森林)后的类向量串行,具体过程大概如下: 每次滑动窗口选出来的特征经过随机森林和完全随机森林经过多个森林建模后得到类向量,串联类向量作为新的特征作为下一级的输入层 - 假设原始特征长度为m,滑动窗口长度为n(n < m),滑动窗口个数:[n, m]即共有m-n+1个滑动窗口
- 可以并行接入不同窗口做Pooling操作
4. 参考资料
[1] Deep Forest: Towards An Alternative to Deep Neural Networks,Zhi-Hua Zhou and Ji Feng,2017.02.28
[2] http://it.sohu.com/20170302/n482153688.shtml