Deep Neural Networks
1. 人工神经网络介绍
https://zh.wikipedia.org/wiki/人工神经网络
2. DNN与传统机器学习方法对比
- 优点
- 降低或避免对特征工程的依赖,深度学习能做特征工程就是因为深度或广度,再加上非线性激励使得更多的组合特征出现,用损失函数来约束整个网络的发展方向,结果就是选择出来的比较容易过拟合的特征。但是这些特征没有什么可解释性,跟多是黑盒
- 缺点
- 黑盒模型
- 需要大样本支撑
- 对硬件要求高
3. DNN基本结构
输入层,隐藏层,隐藏层,… , 输出层
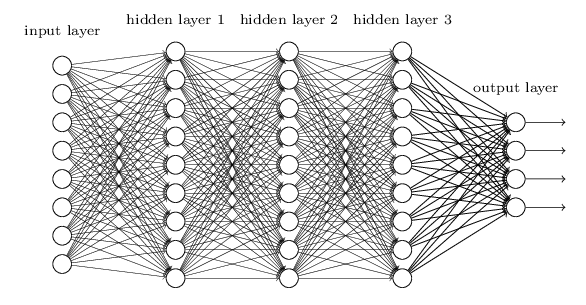
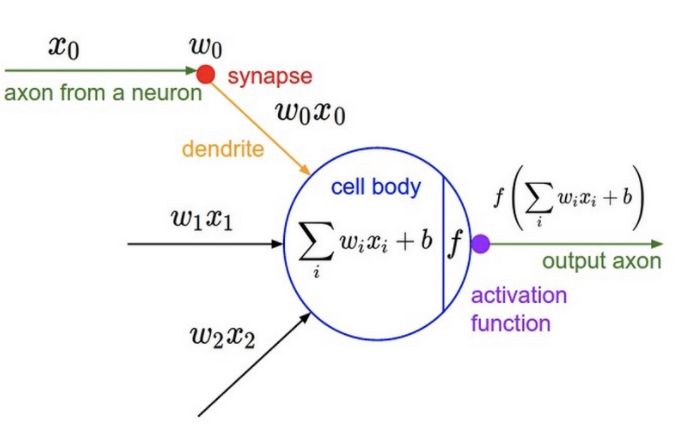
4. 激励函数
激励函数的作用,增加非线形特征映射。激励函数的对比见:Must Know Tips/Tricks in Deep Neural Networks
4.1. Sigmoid函数
\[f(x) = \frac{1}{1+e^{-x}}\]
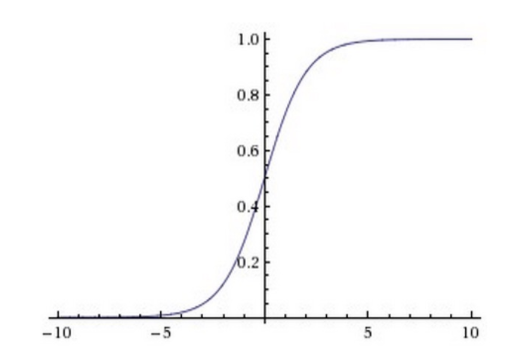
4.2. tanh函数
\[ tanh(x) = \frac{\sinh(x)}{\cosh(x)} = \frac{e^x - e^{-x}}{e^x + e^{-x}} \]
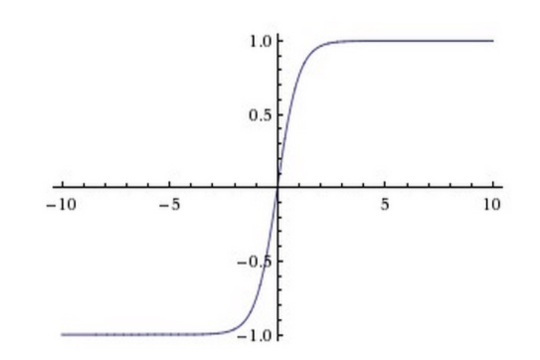
4.3. Relu
\[f(x) = \max(0, x)\]
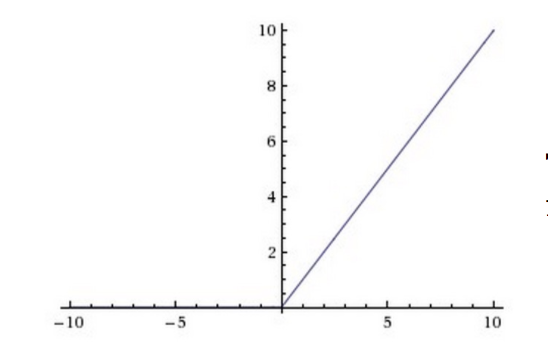
4.4. Leaky ReLU
\[ f(x) = \left\{ \begin{aligned} x,& x \geqslant 0 \\ \alpha x, & x < 0 \\ \end{aligned} \right. \]
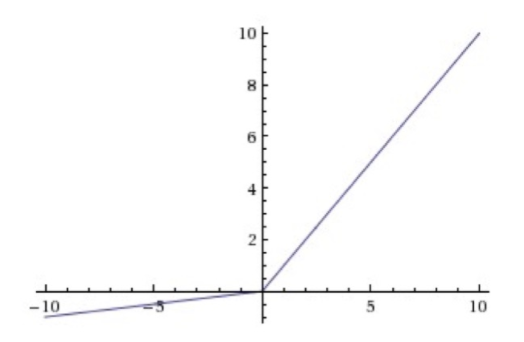
更多激励函数见wiki
5. 神经网络训练方法
小批量梯度下降(Mini-batch Stochastic Gradient Descent)
小批量随机梯度下降较全量样本的梯度下降特点:
- 收敛速度快,收随机梯度下降只是用少量的样本即可完成一次迭代
- 可以跳出局部最优解,找到更接近的全局最优的解,这大概是DNN随机梯度下降而不是全量梯度下降的最直接原因
5.1. 参数训练流程
1,定义损失函数,初始化参数:
2,正向传播得到损失
3,反向传播更新参数
4,判断是停止,否:则跳转到第2步
5.2. 反向传播算法
Backpropagation,BP
由最后一层逐层向前更新参数的算法
5.2.1. 剃度计算及BP推导
以全链接方式(图一)为结果,图二的方式的神经元链接方式为例:
- 符号说明:
- \(W_{i, j, k}\):第\(i\)层神经元的第\(j\)个神经元与第\(i+1\)层的第\(k\)个神经元的链接权重
\(O_{i, j}\):第\(i\)层神经元的第\(j\)个神经元的数学表达式
\[ O_{i\ \ ,\ \ j_{i}} = \left\{ \begin{aligned} & f\Bigg(\sum_{j_{i-1}\ \ =1}^{J_{i-1}} W_{i-1\ \ , \ \ j_{i-1}\ \ ,\ \ j_{i}} \cdot O_{i-1\ \ , \ \ j_{i-1}} + b_{i\ \ ,\ \ j_{i}} \Bigg) \ \ \ & & 当O_{i\ ,\ \ j_{i}}为神经元 \\ & x_{i\ ,\ j_{i}} & & 当O_{i\ ,\ j_{i}}为原始输入时 \end{aligned} \right. \tag{1} \]
\(J_{i}\): 第\(i\)层神经元个数
\(IN_{i,\ j_i}\): 第\(i\)层的第\(j_i\)个神经元激励函数输入值的数学表达式,图2中激励函数f输入部分的数学表达式 \[ IN_{i,\ j_i} = \sum_{j_{i-1}\ \ =1}^{J_{i-1}} W_{i-1\ \ , \ \ j_{i-1}\ \ ,\ \ j_{i}} \cdot O_{i-1\ ,\ j-1} + b_{i\ ,\ j_{i}} \tag{2} \]
- \(V_{IN_{i,\ j_i}}\):第\(i\)层的第\(j_i\)个神经元的\(IN_{i,\ j_i}\)的值,图2激励函数的输入部分数值
\(f^\prime \big(V_{IN_{i,\ j_i}} \ \big)\):第\(i\)层的第\(j_i\)个神经元的激励函数(或损失函数)导数在\(V_{IN_{i,\ j_i}}\)处的数值
考虑第\(i\)层的第\(j\)个神经元与\(i+1\)层的第\(k\)神经元之间的链接权重\(W_{i, j, k}\)的,气候其后面链接神经元的计算表达式中含有\(W_{i, j, k}\)项的是:第\(i+1\)层第\(k\)个神经元,第\(i+2\)层到到\(n\)层的所有神经元
\[ \begin{aligned} &\frac{\partial{O_{n,\ j_{n}} }}{\partial W_{i,\ j,\ k}} \\ = & \left.\frac {\partial f(x)} {\partial x } \right|_{x=V_{IN_{n\ ,\ j_{n}}}} \ \cdot \ \frac {\partial \Big( b_{n, x} + \ \sum_{j_{n-1}\ =1}^{J_{n-1}} O_{n-1, \ j_{n-1}} \ \cdot \ W_{n-1,\ j_{n-1}\ \ ,\ j_{n}} \ \Big) } {\partial W_{i,\ j,\ k}} \\ = & f^\prime \big(V_{IN_{n,\ j_{n}}} \ \big) \ \cdot \ \sum_{j_{n-1}\ \ =1}^{J_{n-1}} W_{n-1,\ j_{n-1}\ \ , \ j_{n}} \ \cdot \ \frac{\partial{O_{n-1,\ j_{n-1}} }}{\partial W_{i,\ j,\ k}} \\ \end{aligned} \tag{3} \]
直接推导(剃度的通项公式): \[ \begin{aligned} \frac{\partial{O_{n\ ,\ j_{n}} }}{\partial W_{i\ ,\ j\ ,\ k}} = & f^\prime \big(V_{IN_{n\ ,\ j_{n}}} \ \big) \ \cdot \ \sum_{j_{n-1}\ \ =1}^{J_{n-1}} W_{n-1\ ,\ j_{n-1}\ , \ x} \ \cdot \ \frac{\partial{O_{n-1\ ,\ j_{n-1}} }}{\partial W_{i\ ,\ j\ ,\ k}} \\ = & \sum_{j_{n-1}\ \ = \ 1}^{J_{n-1}} f^\prime \big(V_{IN_{n\ ,\ j_{n}}} \ \big) \ \cdot \ W_{n-1\ ,\ j_{n-1}\ \ , \ j_{n}} \ \cdot \ \frac{\partial{O_{n-1\ ,\ j_{n-1}} }}{\partial W_{i\ ,\ j\ \ ,\ k}} \\ = & \sum_{j_{n-1}\ \ = \ 1}^{J_{n-1}} f^\prime \big(V_{IN_{n\ ,\ j_{n}}} \ \ \ \big) \ \cdot \ W_{n-1\ ,\ j_{n-1}\ \ , \ j_{n}} \ \cdot \ \Bigg( \sum_{j_{n-2}\ \ = \ 1}^{J_{n-2}} f^\prime \big(V_{IN_{n-1,\ j_{n-1}}} \ \ \ \big) \ \cdot \ W_{n-2\ ,\ j_{n-2}\ \ , \ j_{n-1}} \ \cdot \ \frac{\partial{O_{n-2\ ,\ j_{n-2}} }}{\partial W_{i\ ,\ j\ \ ,\ k}} \Bigg) \\ = & \sum_{j_{n-1}\ \ = \ 1}^{J_{n-1}} \ \ \sum_{j_{n-2}\ \ = \ 1}^{J_{n-2}} \ \cdot\ f^\prime \big(V_{IN_{n\ ,\ j_{n}}} \ \ \ \big) \ \cdot \ W_{n-1\ ,\ j_{n-1}\ \ , \ j_{n}} \ \cdot \ f^\prime \big(V_{IN_{n-1,\ j_{n-1}}} \ \ \ \big) \ \cdot \ W_{n-2\ ,\ j_{n-2}\ \ , \ j_{n-1}} \ \cdot \ \frac{\partial{O_{n-2\ ,\ j_{n-2}} }}{\partial W_{i\ ,\ j\ \ ,\ k}} \\ = & \dots \\ = & \sum_{j_{n-1}\ \ = \ 1}^{J_{n-1}}\ \ \sum_{j_{n-2}\ \ = \ 1}^{J_{n-2}} \dots \sum_{j_{i+2}\ \ = \ 1}^{J_{i+2}} \ \cdot\ f^\prime \big(V_{IN_{n\ ,\ j_{n}}} \ \ \ \big) \\ & \cdot \Big(W_{n-1\ ,\ j_{n-1} \ \ , \ j_{n}} \ \cdot\ f^\prime \big(V_{IN_{n-1\ ,\ j_{n-1}}} \ \ \ \big) \Big) \\ & \cdot \Big(W_{n-2\ ,\ j_{n-2} \ \ , \ j_{n-1}} \ \cdot\ f^\prime \big(V_{IN_{n-2\ ,\ j_{n-2}}} \ \ \ \big) \Big) \\ &\cdot \dots \cdot\ \Big(W_{x\ ,\ j_{x} \ \ , \ j_{x+1}} \cdot f^\prime \big(V_{IN_{x\ ,\ j_{x}}} \ \ \ \big) \Big) \cdot \dots \cdot\ \\ & \cdot\ \Big( W_{i+2\ ,\ j_{i+2} \ \ , \ j_{i+3}} \cdot f^\prime \big(V_{IN_{i+2\ ,\ j_{i+2}}} \ \ \ \big) \Big) \\ & \cdot \ \Big( W_{i+1\ ,\ k \ \ , \ j_{i+2}} \cdot \ \frac{\partial{O_{i+1\ ,\ k} }}{\partial W_{i\ ,\ j\ ,\ k}} \Big) \\ = & \sum_{j_{n-1}\ \ = \ 1}^{J_{n-1}}\ \ \sum_{j_{n-2}\ \ = \ 1}^{J_{n-2}} \dots \sum_{j_{i+2}\ \ = \ 1}^{J_{i+2}} \ \cdot\ f^\prime \big(V_{IN_{n\ ,\ j_{n}}} \ \ \ \big) \\ & \cdot \prod_{x={i+2}}^{n-1}\Big(W_{x\ ,\ j_{x} \ \ , \ j_{x+1}} \cdot f^\prime \big(V_{IN_{x\ ,\ j_{x}}} \ \ \ \big) \Big) \\ & \cdot \ \Big( W_{i+1\ ,\ k \ \ , \ j_{i+2}} \cdot \ \frac{\partial{O_{i+1\ ,\ k} }}{\partial W_{i\ ,\ j\ ,\ k}} \Big) \end{aligned} \tag{4} \]
BP算法推导(剃度的由后往前的递推公式):
\[ \begin{aligned} \frac{\partial{O_{n\ ,\ j_{n}} }}{\partial O_{i+1\ ,\ j_{i+1}}} = & \sum_{j_{n-1}\ \ = \ 1}^{J_{n-1}}\ \ \sum_{j_{n-2}\ \ = \ 1}^{J_{n-2}} \dots \sum_{j_{i+2}\ \ = \ 1}^{J_{i+2}} \ \cdot\ f^\prime \big(V_{IN_{n\ ,\ j_{n}}} \ \ \ \big) \\ & \cdot \prod_{x={i+2}}^{n-1}\Big(W_{x\ ,\ j_{x} \ \ , \ j_{x+1}} \cdot f^\prime \big(V_{IN_{x\ ,\ j_{x}}} \ \ \ \big) \Big) \\ & \cdot \ \Big( W_{i+1\ ,\ j_{i+1} \ \ , \ j_{i+2}} \cdot \ 1 \Big) \end{aligned} \tag{5} \]
\[ \begin{aligned} \frac{\partial{O_{n\ ,\ j_{n}} }}{\partial O_{i\ ,\ j_{i}}} = & \sum_{j_{i+1}\ \ = \ 1}^{J_{i+1}} \ \cdot \ \sum_{j_{n-1}\ \ = \ 1}^{J_{n-1}} \sum_{j_{n-2}\ \ = \ 1}^{J_{n-2}} \dots \sum_{j_{i+2}\ \ = \ 1}^{J_{i+2}} \ \cdot\ f^\prime \big(V_{IN_{n\ ,\ k}} \ \big) \\ & \cdot \prod_{x={i+2}}^{n-1}\Big(W_{x\ ,\ j_{x} \ \ , \ j_{x+1}} \cdot f^\prime \big(V_{IN_{x\ ,\ j_{x}}} \ \ \ \big) \Big) \\ & \cdot \Big(W_{i+1\ ,\ j_{i+1} \ \ , \ j_{x+2}} \cdot f^\prime \big(V_{IN_{i+1\ ,\ j_{i+1}}} \ \ \ \big) \Big) \\ & \cdot \ \Big( W_{i\ ,\ j_{i} \ \ , \ j_{i+1}} \Big) \end{aligned} \tag{6} \]
对比式(5),式(6)得: \[ \begin{equation} \boxed{ \frac{\partial{O_{n\ ,\ k} }}{\partial O_{i\ ,\ j_{i}}} = \sum_{j_{i+1}\ \ = \ 1}^{J_{i+1}} \ f^\prime \big(V_{IN_{i+1\ ,\ j_{i+1}}} \ \ \ \ \big) \ \cdot \ W_{i\ ,\ j_{i} \ \ , \ j_{i+1}} \ \cdot \ \frac{\partial{O_{n\ ,\ k} }}{\partial O_{i+1\ ,\ j_{i+1}}} } \ \ \ \ (其中i + 1 \leqslant n) \end{equation} \tag{7} \]
5.2.2. 使用BP + Mini-batch SGD训练的流程
假设损失函数为\(\ell = (y_i - \hat{y})^2\), 第n层输出层,则式(7)中的第n层第k个神经元可以看作是计算损失的单元,即: \[ O_{n, k}=(y_i - \hat{y})^2 \tag{8} \]
\[ V_{IN_{\ell}} = V(O_{n, k}) \tag{9} \]
\[ \ell^\prime \big(V_{IN_{\ell}} \ \big) = 2V_{IN_{\ell}} \tag{10} \]
针对最后一层隐层到输出层的梯度为: \[ \frac{\partial{\ell}}{\partial W_{n\ ,\ j_{n}}} = \ell^\prime \big(V_{IN_{\ell}} \ \big) \cdot \ V_{O_{n\ ,\ j_{n} }} \ \ \ \ j_{n} = 1, 2, \dots , J_{n} \tag{11} \]
\[ \frac{\partial{\ell}}{\partial O_{n\ ,\ j_{n}}} = \ell^\prime \big(V_{IN_{\ell}} \ \big) \cdot \ W_{n\ ,\ j_{n} } \ \ \ \ j_{n} = 1, 2, \dots , J_{n} \tag{12} \]
则,针对任意层的神经元反向传播梯度为: \[ \begin{aligned} & \frac{\partial{\ell}}{\partial O_{i\ ,\ j_{i}}} = \sum_{j_{i+1}\ \ = \ 1}^{J_{i+1}} \ f^\prime \big(V_{IN_{i+1\ ,\ j_{i+1}}} \ \ \ \big) \ \cdot \ W_{i\ ,\ j_{i} \ \ , \ j_{i+1}} \ \cdot \ \frac{\partial{\ell}}{\partial O_{i+1\ ,\ j_{i+1}}} \end{aligned} \tag{13} \]
任意层权值\(w\)的反向传播梯度为: \[ \begin{aligned} \frac{\partial{\ell}}{\partial W_{i-1\ \ ,\ j_{i-1}\ \ , \ \ j_{i}}} = & \frac{\partial{\ell}}{\partial O_{i\ ,\ j_{i}}} \ \cdot \ \frac{\partial O_{i\ ,\ j_{i}}} {\partial W_{i-1\ \ ,\ j_{i-1}\ \ , \ \ j_{i}}} \\ = & \frac{\partial{\ell}}{\partial O_{i\ ,\ j_{i}}} \ \cdot \ f^\prime \big(V_{IN_{i\ ,\ j_{i}}} \ \big) \ \cdot \ \frac{\partial V_{IN_{i\ ,\ j_{i}}} } {\partial W_{i-1\ \ ,\ j_{i-1}\ \ , \ \ j_{i}}} \\ = & \frac{\partial{\ell}}{\partial O_{i\ ,\ j_{i}}} \ \cdot \ f^\prime \big(V_{IN_{i\ ,\ j_{i}}} \ \big) \ \cdot \ V_{O_{i-1\ \ ,\ j_{i-1}}} \end{aligned} \tag{14} \]
参数范围: \[ \left\{ \begin{aligned} & i = 2, 3, \dots, n-1 \\ & j_i = 1, 2, 3, \dots, J_i \\ & j_{i+1} = 1, 2, 3, \dots, J_{i+1} \end{aligned} \right. \tag{15} \]
将偏移项对应的输入值看看成1,即\(V_{O_{i-1\ \ ,\ j_{i-1}\ \ , \ \ j_{i}}} = 1\),则上式中\(W_{i-1\ \ ,\ j_{i-1}\ \ , \ \ j_{i}}\)可看成是常数1的权重,并且这个权重影响到的是\(O_{i,\ \ j{i}}\), 那么将此权重写作\(b_{i,\ \ j{i}}\)表示第\(i\)层\(j_{i}\)个神经元求和项的偏置 \[ \frac{\partial{\ell}}{\partial b_{i\ \ ,\ j_{i}}} = \frac{\partial{\ell}}{\partial O_{i\ ,\ j_{i}}} \ \cdot \ f^\prime \big(V_{IN_{i\ ,\ j_{i}}} \ \big) \tag{16} \]
对于学习率为\(\alpha\),batch为\(M\)的SGD权值逐层更新公式如下: \[ \boxed{ W_{i-1\ \ ,\ j_{i-1}\ \ , \ \ j_{i}} = W_{i-1\ \ ,\ j_{i-1}\ \ , \ \ j_{i}} - \alpha \cdot \sum_{m=1}^{M} \frac{\partial{\ell}}{\partial W_{i-1\ \ ,\ j_{i-1}\ \ , \ \ j_{i}}} } \tag{17} \]
5.2.3. 反向传播简单例子
\[f(\boldsymbol{x}) = \frac{1}{1 + \exp^{-(w_{0} x_{0} + w_{1} x_{1} + w_{2})}}的BP示意图 \]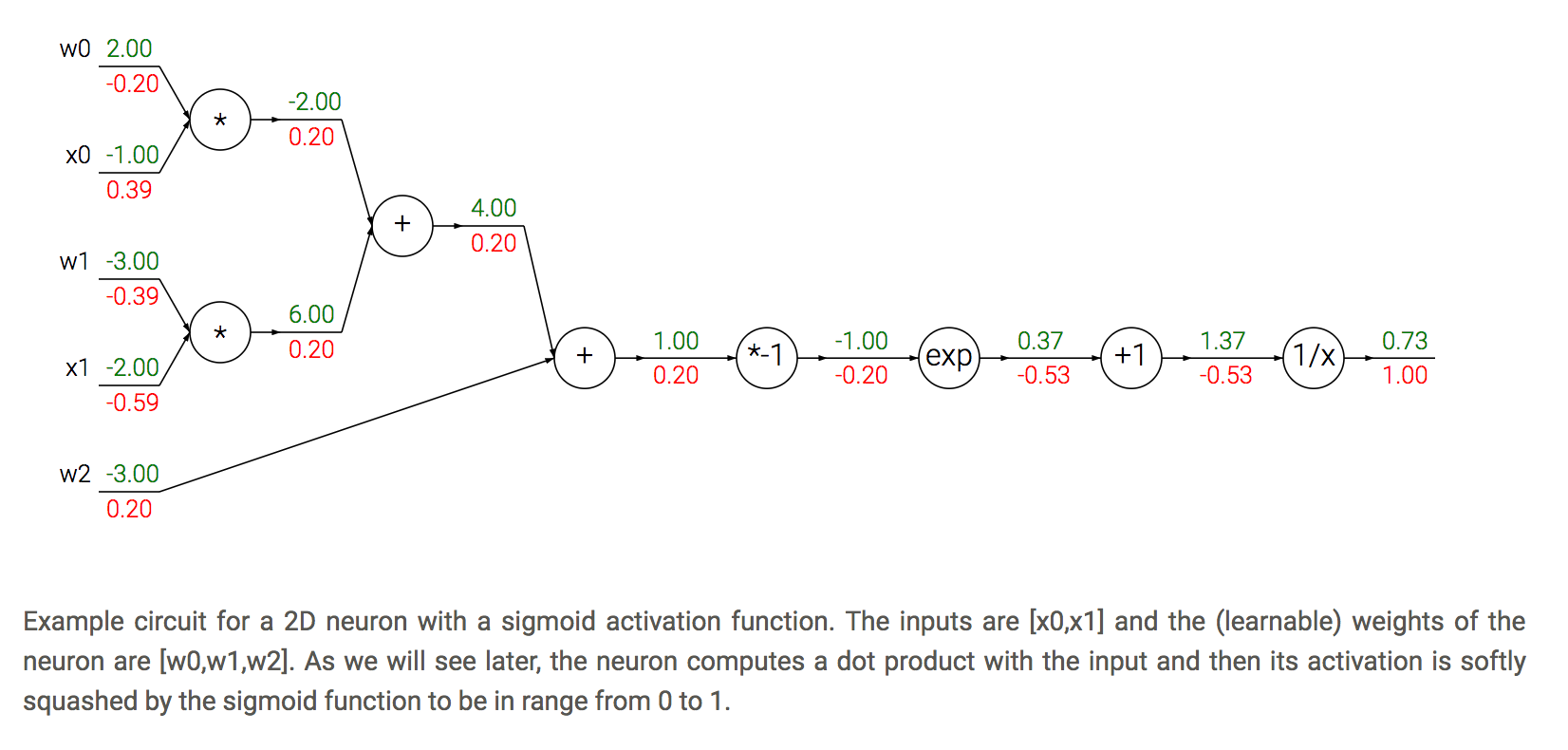
5.3. Xavier参数初始化
2010 Xavier Glorot, Yoshua Bengio Understanding the difficulty of training deep feedforward neural networks, http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
https://www.tensorflow.org/versions/r0.11/api_docs/python/contrib.layers/initializers
http://blog.csdn.net/app_12062011/article/details/57956920
5.3.1. 问什么要使用初始化
主要目的是使的训练更容易进行下去
考虑计算机的数值运算时的上溢及下溢存在,对应避免方差过大导致剃度爆炸及剃度消失
5.3.2. 基本假设
输入样本x,权重w,偏置b分别服从均值为0的分布,所有样本属于独立同分布,所有权重属于独立同分布
关于原点对称的激活函数,即满足\(f^\prime(x) \approx 1\),满足该条件的激励函数有Softsig, tanh, relu,所以以下讨论只是针对这些激励函数,而不包括sigmoid函数。
因为激励函数的0导数为1,且在x,w,b均值为0的假设下,每个神经元激励的输入的均值0附近。为了方便推导,将激励函数近似成线性函数 即,对于激励函数的输入\(In\),激励函数的出处\(Out\) \[Out=f(In)=In \tag{18}\]
5.3.3. 方差公式
用到的几个方差公式
如果有均值为0的两个互相独立的变量\(x\), \(y\)。则\(Var(xy) = Var(x) Var(y)\)
对于常数\(a\),有\(Var(x+a) = Var(x)\)
5.3.4. 目标函数
5.3.4.1. 保证正向传播方差一致
任意两层网络激励函数的输出方差相等.
目标函数 \[ \forall(i, i^\prime),\ \ Var[O^{i}] = Var[O^{i^\prime}] \tag{19} \]
根据式(2), \[ IN_{i,\ j_i} = \sum_{j_{i-1}\ \ =1}^{J_{i-1}} W_{i-1\ \ , \ \ j_{i-1}\ \ ,\ \ j_{i}} \cdot O_{i-1\ \ , \ \ j_{i-1}} + b_{i\ ,\ j_{i}} \]
激励函数输入经过经过激励函数后得到激励函数的输出: \[ O_{i,\ j_i} = f(IN_{i,\ j_i}) \]
利用式(19)的激励函数的近似得 \[ O_{i,\ j_i} = \sum_{j_{i-1}\ \ =1}^{J_{i-1}} W_{i-1\ \ , \ \ j_{i-1}\ \ ,\ \ j_{i}} \cdot O_{i-1\ \ , \ \ j_{i-1}} + b_{i\ ,\ j_{i}} \]
计算方差 \[ Var(O_{i,\ j_i}) = \sum_{j_{i-1}\ \ =1}^{J_{i-1}} Var(W_{i-1\ \ , \ \ j_{i-1}\ \ ,\ \ j_{i}}) \cdot Var(O_{i-1\ \ , \ \ j_{i-1}} ) \]
合并相同方差 \[ Var(O_{i}) = J_{i-1} Var(W_{i-1}) \cdot Var(O_{i-1}) \]
可以将以上递推公式展开得到论文中的形式,但是使用递推公式既可得到结论
要使得目标函数成立,需使得每一层的神经元输出的方差都和下一层相同,即,需使得 \[ J_{i} Var(W_{i}) = 1 , \ \ i = 1, 2, \cdots, n \tag{20} \]
5.3.4.2. 保证反向传播的方差一致
任意两层网络的损失损失对激励层输入的导数相等
目标函数:
\[
\forall(i, i^\prime),\ \ \frac{\partial{\ell}}{\partial IN_{i}} = \frac{\partial{\ell}}{\partial IN_{i^\prime}} \tag{21}
\]
在式(5),式(6),式(7)的基础上可以容易得到: \[ \frac{\partial{\ell }}{\partial IN_{i\ ,\ j_{i}}} = \sum_{j_{i+1}\ \ = \ 1}^{J_{i+1}} \ \cdot \ W_{i\ ,\ j_{i} \ \ , \ j_{i+1}} \ f^\prime \big(V_{IN_{i\ ,\ j_{i}}} \big) \ \cdot \ \frac{\partial{\ell}}{\partial IN_{i+1\ ,\ j_{i+1}}} \] 计算方差 \[ Var(\frac{\partial{\ell }}{\partial IN_{i\ ,\ j_{i}}}) = \sum_{j_{i+1}\ \ = \ 1}^{J_{i+1}} \ \cdot \ Var(W_{i\ ,\ j_{i} \ \ , \ j_{i+1}}) \ \cdot \ Var(f^\prime \big(V_{IN_{i\ ,\ j_{i}}} \big)) \ \cdot \ Var(\frac{\partial{\ell}}{\partial IN_{i+1\ ,\ j_{i+1}}}) \] 相等方差合并 \[ Var(\frac{\partial{\ell }}{\partial IN_{i}}) = J_{i+1}\ \cdot \ Var(W_{i}) \ \cdot \ Var(\frac{\partial{\ell}}{\partial IN_{i+1}}) \]
则,要使得式(20)成立,需使得 \[ J_{i+1}Var(W_{i}) = 1, \ \ i = 1, 2, \cdots, n \tag{22} \]
5.3.5. 结论
当\(J_{i} \neq J_{i+1}\) 时式(20)和式(22)同时满足的话是矛盾的,但是论文中提出了一种折中方法,使用两种情况的调和平均数 \[ Var(W_{i}) = \frac{2}{J_{i} + J_{i+1}} \]
均值为0的均匀分布可以表示为[-a, a]。令其方差为\(\frac{2}{J_{i} + J_{i+1}}\),则有 \[ \frac{(a-(-a))^2}{12} = \frac{2}{J_{i} + J_{i+1}} \] 得 \[ a = \frac{\sqrt{6}}{\sqrt{J_{i} + J_{i+1}}} \]
则 \[ w \sim U\Bigg[-\frac{\sqrt{6}}{\sqrt{J_{i} + J_{i+1}}}, \frac{\sqrt{6}}{\sqrt{J_{i} + J_{i+1}}}\Bigg] \tag{23} \]
5.3.6. 特别说明
- 式(23)是针对激励函数\(f\),有\(f^\prime(x) \approx 1\),且有\(f(0)=0\)条件的推导。基于以上两个条件近似f(x)=x。所以上面推导并不适用于sigmoid激励函数。
- 因为推导过程中激励函数使用了近似,另外正反向传播方差方差的不一致使用了折中的调和平均,所以针对特别深的网络Xavier初始化并不总是有用。
- 因为使用了激励函数的近似在0处的近似替代,则数据输入层尽可能在均值为0,可以去均值或归一化等。
5.4. Batch Normalization
主要参考:https://arxiv.org/abs/1502.03167
为了避免梯度消失导致深度神经网络无法训练的情况,通常使用relu激励函数+vavier的权值初始化方式
如果使用sigmoid的情况下,尽量使得各个神经元求和之后尽量为均值为0的高斯分布中,
将过激励函数的输入数据的每一个维的数据标准化到均值为0,方差为1的正太分布。即,使得\(\hat{x}^{(k)} \scriptsize{\sim} N(0, 1)\)
5.4.1. BN的作用
Batch Normalizaiton作用基本同Xavier初始化,不同的是,BN层不是从初始化考虑的,而是更直接在激励层输入之前强制标准化成固定均值及方差的高斯分布中。
整体来说有以下特点:
1,对初始化权重参数没有要求 2,允许训练过程以高学习率来训练网络而不至于提督消失或剃度爆炸 3,可以提高网络的泛化能力,降低对dropout的依赖
5.4.2. BN基本思想
1,将每一个维度的数据分布标准化到均值为0,方差为1的高斯分布中去
2,针对强行把数据分布拉到高斯分布的数据再进行线形变换,补偿一部分标准化过程中数据压缩。大概思维同卷积神经网络的卷积和池化层之后接全链接层
5.4.3. BN层的训练过程中的正向传播
使用m个样本更新参数时,m个样本的的某一个维度为例,下式中\(x_i\)代表第\(i\)个样本的第\(k\)个分量。\(\beta\),\(\gamma\)为未知参数,每层每个分量的共享,需要通过训练。\(\mu\),\(\sigma^2\):是由参与更新的的这个batch决定的
5.4.4. BN层的使用
使用过程同正向传播,只是针对输入样本是其均值和方差由多个mini-batch的均值和方差的期望组成,既有N次mini-batch时:
\[ \mu = E_B[\mu_{B}] \tag{24} \]
\[ \sigma ^ 2 = \frac{m}{m-1}E_B[\sigma_{B} ^ 2] \tag{25} \]
\[ \hat{x_i} = \frac{x_i - \mu}{\sqrt{\sigma ^ 2 + \epsilon}} \tag{26} \]
\[ y_i = \gamma \hat{x_i} + \beta \tag{27} \]
其中\(\epsilon\)为较小的数,防止分母为0的情况发生
5.4.5. 含有BN层的BP传播
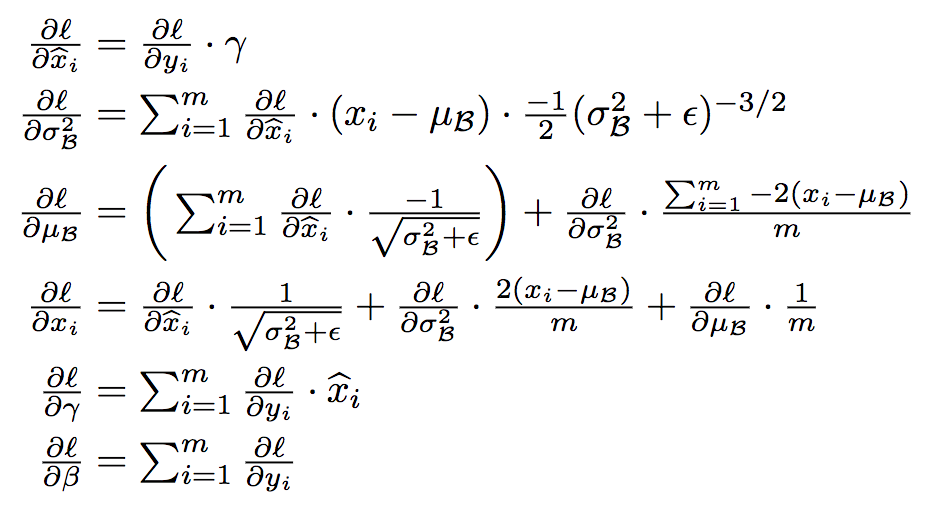
则根据式(13) \[ \begin{aligned} & \frac{\partial{\ell}}{\partial y_{i\ ,\ j_{i}}} = \sum_{j_{i+1}\ \ = \ 1}^{J_{i+1}} \ f^\prime \big(V_{IN_{i+1\ ,\ j_{i+1}}} \ \big) \ \cdot \ W_{i\ ,\ j_{i} \ \ , \ j_{i+1}} \ \cdot \ \frac{\partial{\ell}}{\partial O_{i+1\ ,\ j_{i+1}}} \end{aligned} \tag{28} \]
则根据BN层的导数计算公式容易得到:
\[ \frac{\partial{\ell}}{\partial x_{i\ ,\ j_{i}}} \tag{29} \]
\[ \frac{\partial{\ell}}{\partial \gamma_{i\ ,\ j_{i}}} \tag{30} \]
\[ \frac{\partial{\ell}}{\partial \beta_{i\ ,\ j_{i}}} \tag{31} \]
为了和式(13)保持一致,更新式(13)为 \[ \frac{\partial{\ell}}{\partial O_{i\ ,\ j_{i}}} = \frac{\partial{\ell}}{\partial x_{i\ ,\ j_{i}}} \tag{32} \] 上式表示,损失对经过激励函数输出的剃度,至此含有BN层和没有BN层的反向传播从形式上得到统一
5.5. Dropout
http://www.jmlr.org/papers/volume15/srivastava14a.old/source/srivastava14a.pdf
控制神经网络过拟合的一种方法
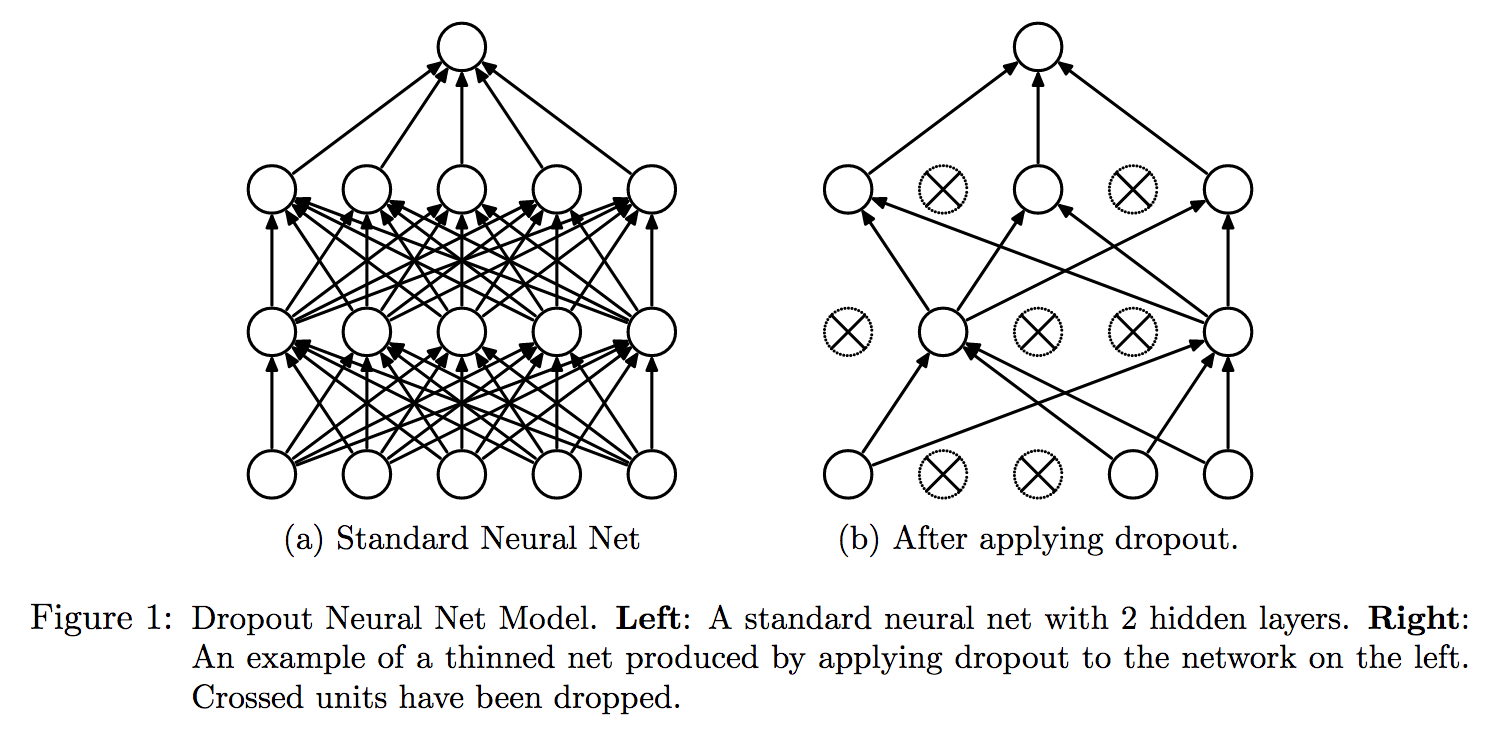
5.5.1. 基本思想
有性繁殖和无性繁殖的区别: 无性生殖因为其遗传的单一性,总能容易的把大段优秀的基因遗传给子代,而有性生殖却不太具备把大段优秀的基因传给下一代。但是有性繁殖是最先进的生物进化方式
论文中提出有性繁殖优于无性繁殖论可能原因, 长期自然进化选择协作能力强的基因的而不是个体,协作方式更加稳健。
另一种理解就是有性繁殖避免了整个基因库走向极端,而不同基因的组合方式将基因多使得样性更容易快速适应不确定的未来。
基于有性繁殖的被保留下来的特性,训练神经网络过程中,不是用所有的神经元,而是一部分神经元。所有有了Dropout
即:每个mini—bath训练时都以一定概率\(p\)随机打开若干神经元(不参与本次运算),多次训练即多种网络结构集成达到控制过拟合的目的
当\(p=0.5\)时熵达到最大,即网络结构数量的期望可以达到最大值,这应该也是论文中提到\(0.5\)的原因
5.5.1.1. 多模型集成
每次训练时神经网络结构都不同, 最后结果是通过多种结构叠加而成, 从这个角度来说Dropout有Bagging的思想
5.5.1.2. 权值共享
考虑针对多个网络结构单独训练参数带来的时间成本,Dropout使用了权值共享策略,即所有网络的权值是相应位置是同一个权值,只是当某些神经元关闭时,该神经元和下一层链接神经元之间的权值不参与更新。从多个模型参数有协同参与完成模型预测的角度来说, Dropout具有Boosting的思想
5.5.2. 算法基本流程
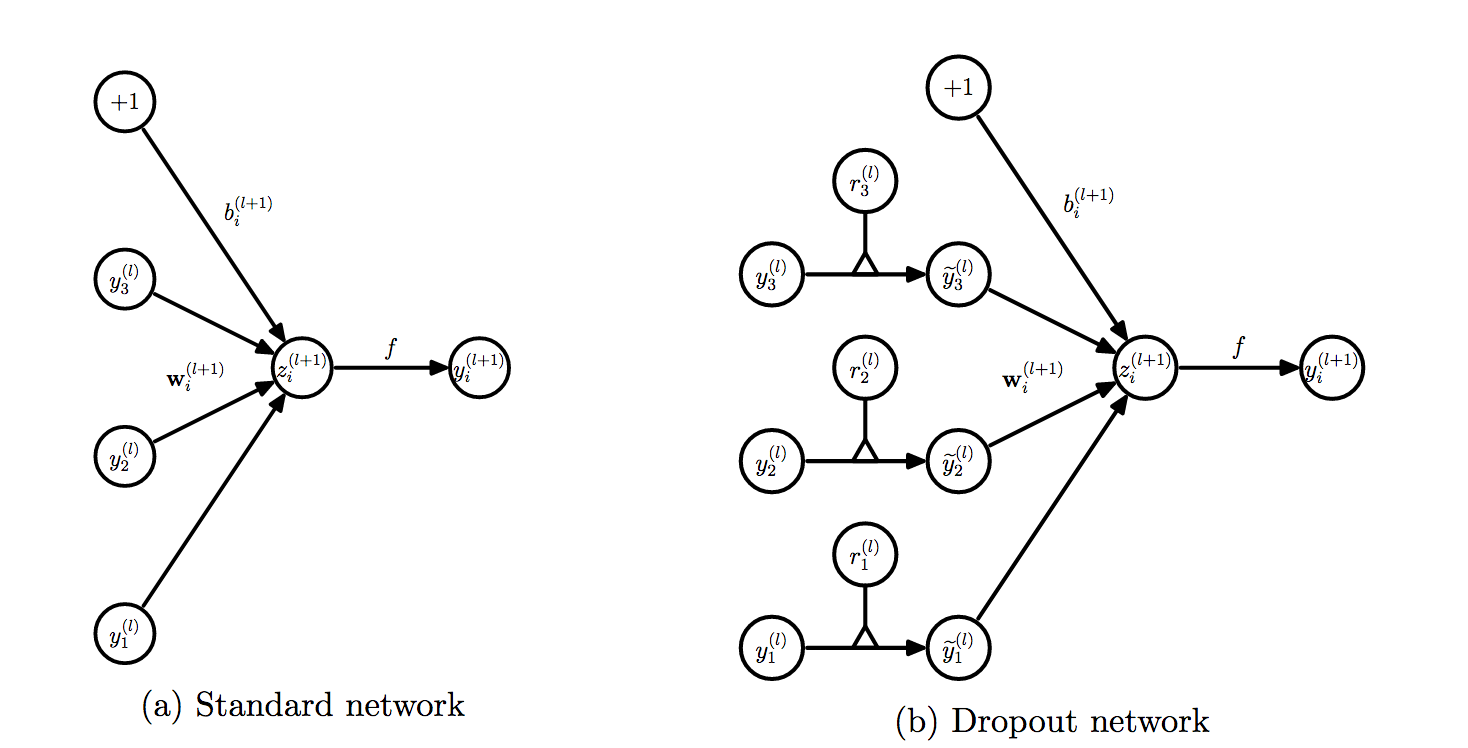
如上图,引入Dropout的神经网络在训练阶段每个神经元之后多了一个开关阀, 即在一次参数更新时,不是所有的神经元被激活
5.5.2.1. 参数训练
初始化所有链接的权重 针对没次训练: 每个神经元以概率\(p\)的情况关闭,即以概率\(p\)打开神经网络的连接, 构建网网络,以之前权重为初始值更新本次有效链接的权值
5.5.2.2. 模型预测
所有神经元的权值乘以概率\(p\),整个网络以未加入dorpout之前的结构进行正向传播进行结果预测。乘以概率\(p\)可以理解为,网络在训练过程中,每个神经元始终是以概率\(p\)参与最后的预测, 所以预测时需要以概率\(p\)来打开,从期望的角度来可以看作是以每个神经元都被打开但其最终作用降为原来的\(p\)倍,既保证了目标一致性的前提下,又使得神经元均参与数据预测,达到提高网络泛化能力的目的
假设训练结果得到某链接的权值为\(w\),预测过程中该神经元的贡献为\(w \cdot x\), 使用过程中该链接对应的值为\(p \cdot w \cdot x\), 假设\(w = \frac{1}{p} \cdot w^\prime\)。则训练过程可以为\(\frac{1}{p} \cdot w^\prime\),模型使用过程中\(w^\prime \cdot x\)。这样可以在使用过程中保证在含有Dropout网络输出的一致性,而不用单独处理
[深度学习中 Batch Normalizat为什么效果好]https://www.zhihu.com/question/38102762
5.6. 其他提高泛化的方法
L0-norm
L1-norm
L2-norm
max-norm
提前终止
6. 参考
[1] 2016.11.11 Ian Goodfellow, Yoshua Bengio, Aaron Courville 《Deep Learning》
[2] 2017.03.15《Deep Learning翻译》https://exacity.github.io/deeplearningbook-chinese/ [3] 2015.03.02 Google Inc Batch Normalization
[4] 2014, Hintorn,etcDropout: A Simple Way to Prevent Neural Networks from Overfitting
[5] https://en.wikipedia.org/wiki/Backpropagation
[6] CS231n Convolutional Neural Networks for Visual Recognition
[7] 2010 Xavier Glorot, Yoshua Bengio Understanding the difficulty of training deep feedforward neural networks, http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
[8] TensorFlow.contrib.layers.xavier_initializer
[9] 权重初始化Xavier
[10] Must Know Tips/Tricks in Deep Neural Networks